Production AI agents have moved from impressive demos into operational workflows. The question is no longer only, "Can the model answer correctly?" It is now, "Can we explain, reproduce, govern, and safely stop an agent run after it has retrieved data, called tools, changed state, and influenced a business process?"
Not every agent failure throws an exception. A model call can complete successfully, a tool can return 200 OK, latency can stay within budget, and the overall outcome can still be wrong. A stale retrieval result in step two can become trusted context in step seven. A tool call with a subtly incorrect parameter can distort a downstream business metric days later. A hallucinated intermediate assumption can be carried through a multi-agent workflow as if it were verified fact.
Traditional observability is necessary, but it is no longer sufficient. Production agents need an additional systems layer: agent observability. That layer must capture the agent's execution graph - session state, prompt and template versions, retrieval lineage, tool calls, policy decisions, evaluation signals, and business outcomes.
The Enterprise Signal: Governance Is Becoming Part of the Agent Platform
The governance gap is already visible at the data layer. Liquibase's 2026 State of Database Change Governance Report says 96.5% of surveyed organizations report at least one AI or LLM interaction with production databases. The same report highlights a maturity gap: only 7.7% report fully automated governance using policy as code with real-time enforcement. [1]
This does not mean every enterprise has autonomous agents writing to production systems. The more accurate conclusion is narrower and more important: AI is already touching operational data through analytics, reporting, internal copilots, model pipelines, and AI-generated SQL. That is enough to make observability and governance an infrastructure concern, not a research concern. [2]
The platform market is responding. At Google Cloud Next '26, Google announced the Gemini Enterprise Agent Platform as a comprehensive platform to build, scale, govern, and optimize agents. Google's announcement explicitly includes capabilities such as Agent-to-Agent Orchestration, Agent Registry, Agent Identity, Agent Gateway, and Agent Observability. [3] [4]
Adobe made a similar move the same week with Adobe CX Enterprise, which it describes as an end-to-end agentic AI system combining AI agents, agent skills, Model Context Protocol endpoints, and an intelligence and governance layer for reliable and auditable workflows. [5]
The signal is clear: production readiness is shifting from model capability alone to the surrounding control plane - observability, identity, policy enforcement, evaluation, and auditability.
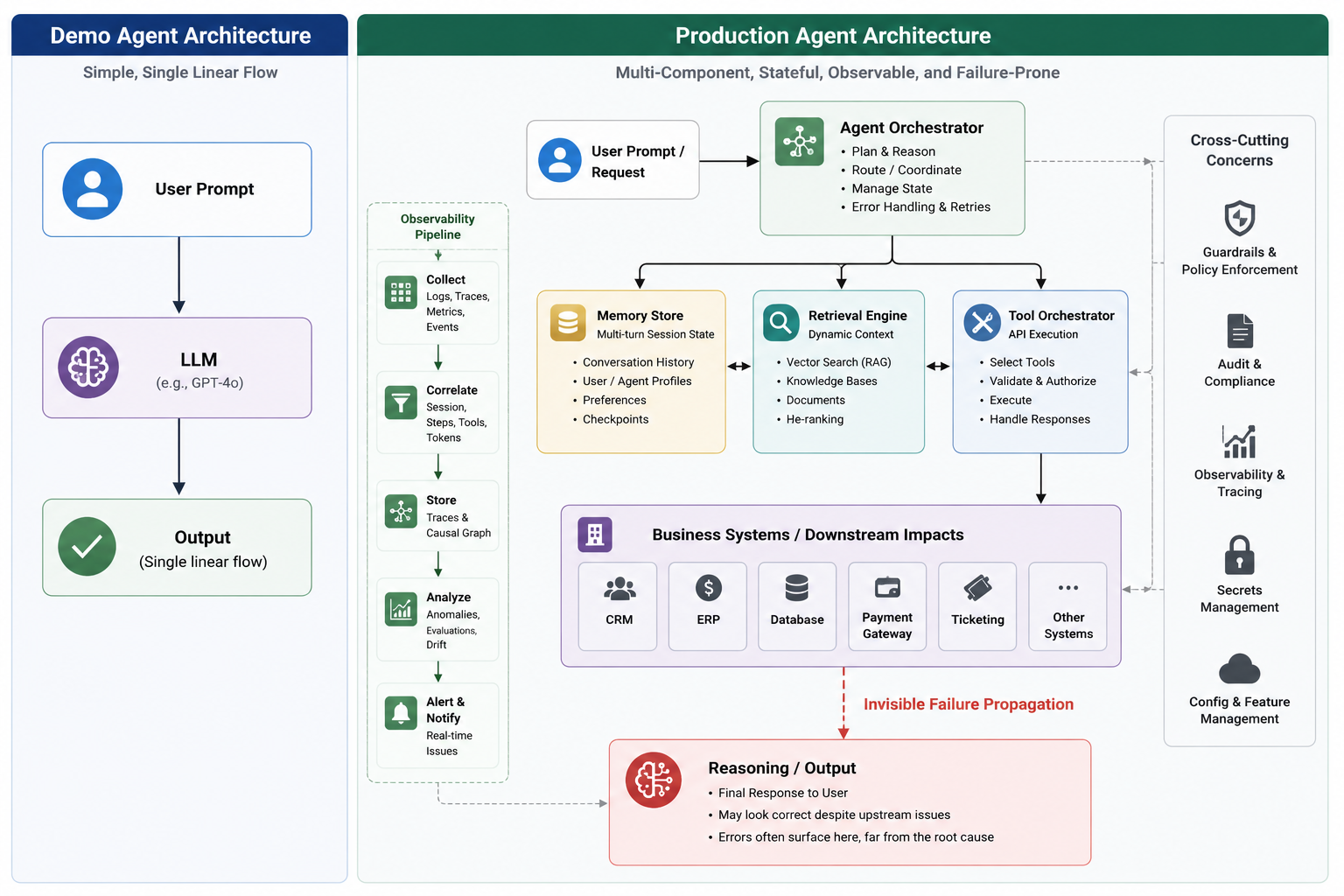
Why Traditional Monitoring Is Incomplete for Agent Systems
Logs, metrics, and service-level traces still matter. They tell you whether an API was slow, whether a dependency failed, whether token cost spiked, or whether an exception occurred. But agent failures are often semantic rather than mechanical.
A traditional dashboard can show that every component was healthy while missing the actual failure path: the agent retrieved the wrong document, used it to build a plausible prompt, called the correct tool with the wrong parameter, then produced an answer that looked confident and passed schema validation.
That is why standard observability has to be extended with AI-semantic tracing. OpenTelemetry's generative AI semantic conventions define how model calls and tool-call behavior can be represented as spans and attributes. [6] OpenInference, built on OpenTelemetry, goes further by standardizing traces across LLM calls, agent steps, tool invocations, retrieval operations, and final responses. [7]
Agent systems break conventional assumptions in four ways:
- They are long-lived. A session can span minutes, hours, or days, and memory can influence later actions.
- They are dynamic. The tool path is often chosen at runtime, not hard-coded into a fixed request path.
- They are context-sensitive. Retrieval results, memory state, prompt templates, model versions, and policy rules all shape the outcome.
- They can create delayed side effects. A bad tool call might not fail immediately; it might surface later as a wrong invoice, misrouted ticket, bad customer segment, or corrupted report.
Common silent failure modes include:
- Retrieval drift: the agent retrieves stale, incomplete, or unauthorized context and reasons correctly over the wrong evidence.
- Tool-call lineage gaps: the agent calls the right tool with subtly wrong parameters, and the downstream effect is discovered only after business metrics shift.
- Context or memory poisoning: bad intermediate state becomes future context.
- Evaluator blind spots: the final answer passes a formatting or tone check while failing the actual domain requirement.
- Excessive agency: the agent performs an action outside the intended permission, workflow, or risk boundary.
These are not just reliability concerns. They are also security and governance concerns. OWASP's 2026 work on agentic applications identifies autonomous and agentic systems as a distinct risk category that needs dedicated security controls. [8]
What Agent Observability Must Capture
Agent observability is the ability to reconstruct what happened across the full execution path of an agent run. In practice, that means more than tracing a single model call. A useful trace should show the request as a tree of related operations: the user turn, prompt construction, retrieval events, model calls, tool invocations, policy checks, evaluator outputs, side effects, and final response. [7]
A production-grade trace should capture:
- Session identity and correlation IDs across the agent, tools, services, and downstream systems.
- Prompt and template versions, including system instructions, developer instructions, and parameterized templates.
- Model metadata, including provider, model version, temperature, token usage, latency, and failure status.
- Retrieval lineage, including corpus version, document IDs, chunk IDs, freshness, filters, permissions, and relevance scores where available.
- Tool invocation lineage, including exact input schema, output schema, status, retries, timeout behavior, and side-effect identifiers such as transaction IDs.
- Policy and guardrail decisions, including what was allowed, blocked, escalated, or sent for human approval.
- Evaluation signals, including grounding, tool correctness, policy compliance, format validity, safety, and domain-specific success criteria.
- Business outcome links, such as invoice approval accuracy, ticket resolution time, conversion impact, case deflection quality, or incident cost.
One important distinction: observability does not require logging raw hidden chain-of-thought. In many systems, that is either unavailable, undesirable, or unsafe to store. The more reliable pattern is to capture observable intermediate events: plans exposed by the agent runtime, tool choices, retrieved evidence, policy decisions, evaluator scores, and state transitions. Google Cloud's guidance on reliable agents similarly distinguishes reasoning traces from system traces and argues that both are needed to debug agent behavior. [9]
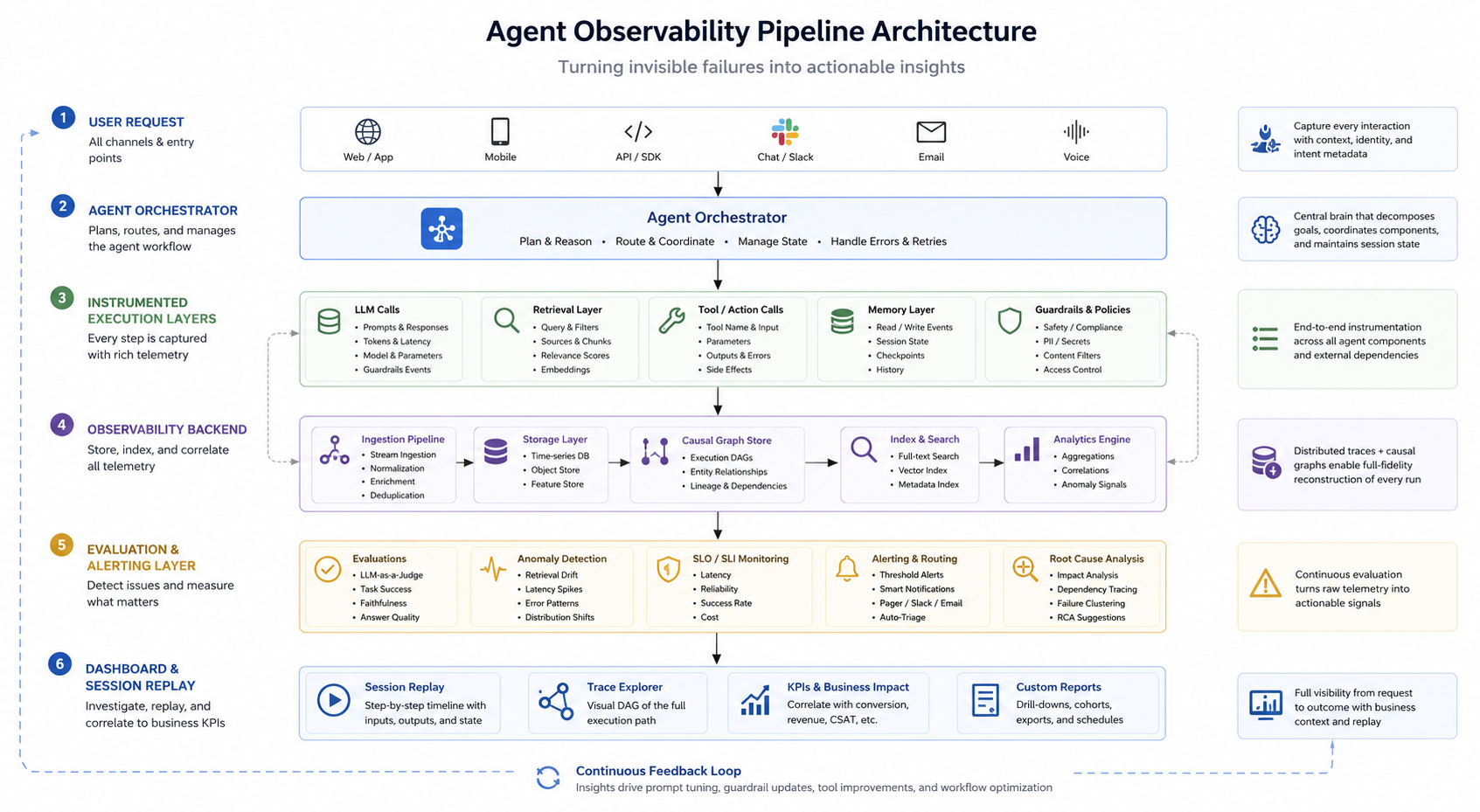
The Production Readiness Checklist
For teams moving agents into high-stakes workflows, the minimum bar should be higher than "the final response looked good." A practical readiness checklist looks like this:
- Instrument every step. Use OpenTelemetry-compatible spans or an AI-semantic tracing standard so model calls, retrieval steps, tool calls, policy checks, and evaluator results are part of one trace.
- Propagate session context. Carry the same trace ID, session ID, user or actor ID, and agent ID across the orchestrator, tools, APIs, queues, and databases.
- Version the context layer. Record corpus version, retriever configuration, ranking model, filters, top-k settings, prompt template version, and citation metadata.
- Log tool calls safely. Capture input and output schemas, execution metadata, retries, and side-effect IDs. Redact secrets, credentials, personal data, and regulated data before telemetry leaves the runtime.
- Evaluate incrementally. Add lightweight evaluators at major steps, not only at the final output. Check grounding after retrieval, tool correctness after invocation, and policy compliance before action.
- Add policy gates. Require human approval, risk scoring, or automatic blocking for high-impact actions such as database mutation, payment approval, legal advice, customer communication, or permission changes.
- Enable replay where feasible. Store the artifacts needed to reproduce or approximate a run: prompt versions, model settings, retrieved context, tool responses, policy versions, and external-service mocks. Deterministic replay is not always possible with probabilistic models and live tools, so the goal is controlled replay, diffing, and root-cause analysis.
- Correlate traces to KPIs. Connect technical behavior to business outcomes: accuracy, resolution time, escalation rate, cost per case, refund error rate, user satisfaction, or incident impact.
- Govern retention and access. Agent telemetry often contains sensitive prompts, retrieved records, and tool outputs. Apply retention limits, access controls, encryption, audit logs, and redaction policies.
- Test failure modes before scaling. Simulate stale retrieval, prompt injection, wrong tool selection, tool timeout, low-confidence retrieval, corrupted memory, denied permissions, and policy escalation.
NIST's AI Risk Management Framework is useful here because it frames AI risk management as a continuous lifecycle across governance, mapping, measurement, and management rather than a one-time launch review. [10] Its playbook also emphasizes monitoring, auditing, incident response, data governance, and alignment with broader organizational controls. [11]
The Bottom Line
Demo agents fail visibly. Production agents often fail invisibly.
That difference is the reason agent observability matters. If you cannot reconstruct why an agent took an action, what evidence it used, what tools it called, what policy checks ran, and what business outcome followed, you do not have a governed production system. You have automation without an audit trail.
The next generation of reliable AI systems will not be defined only by larger models or better prompts. It will be defined by the systems layer around the model: tracing, evaluation, identity, policy enforcement, replay, and operational governance.
The teams that build that layer early will move faster, not slower. They will debug faster, earn trust faster, and scale agents with fewer invisible failures.
What is your current approach? Are you implementing session-level tracing and tool-call lineage for your agent deployments, or are you still relying primarily on traditional logs and final-output evaluation?
Sources
- Liquibase, 2026 State of Database Change Governance Report
- Business Wire, Liquibase 2026 Report Finds AI Now Interacts With Production Databases in 96.5% of Organizations as Governance Automation Lags
- Google Cloud Blog, Welcome to Google Cloud Next26
- Google Cloud Blog, Introducing Gemini Enterprise Agent Platform, powering the next wave of agents
- Adobe News, Adobe Redefines Customer Experience Orchestration Vision in the Agentic AI Era with Introduction of CX Enterprise
- OpenTelemetry, Semantic conventions for generative client AI spans
- OpenInference, OpenInference Specification
- OWASP GenAI Security Project, Agentic Security Initiative
- Google Cloud Blog, From "Vibe Checks" to Continuous Evaluation: Engineering Reliable AI Agents
- NIST AI Resource Center, AI RMF Core
- NIST AI Resource Center, AI RMF Playbook - Govern