Production AI agents are moving from useful assistants into operational systems.
They retrieve context. They call tools. They update records. They delegate work. They trigger workflows. They maintain memory. They operate across APIs, databases, documents, and business processes.
That changes the engineering problem.
In previous posts, I argued that production agents need observability because many failures do not appear as traditional software failures, and that agents become privileged runtime layers once they can act across tools, data, APIs, and workflows.
But there is a third problem that sits underneath both:
Execution boundaries.
Observability answers:
What happened during the agent run?
Governance asks:
Was the agent allowed to do what it did?
Execution-boundary design asks:
Did the agent stay inside the safe operational scope while acting?
That question is becoming one of the most important differences between AI demos and production AI systems.
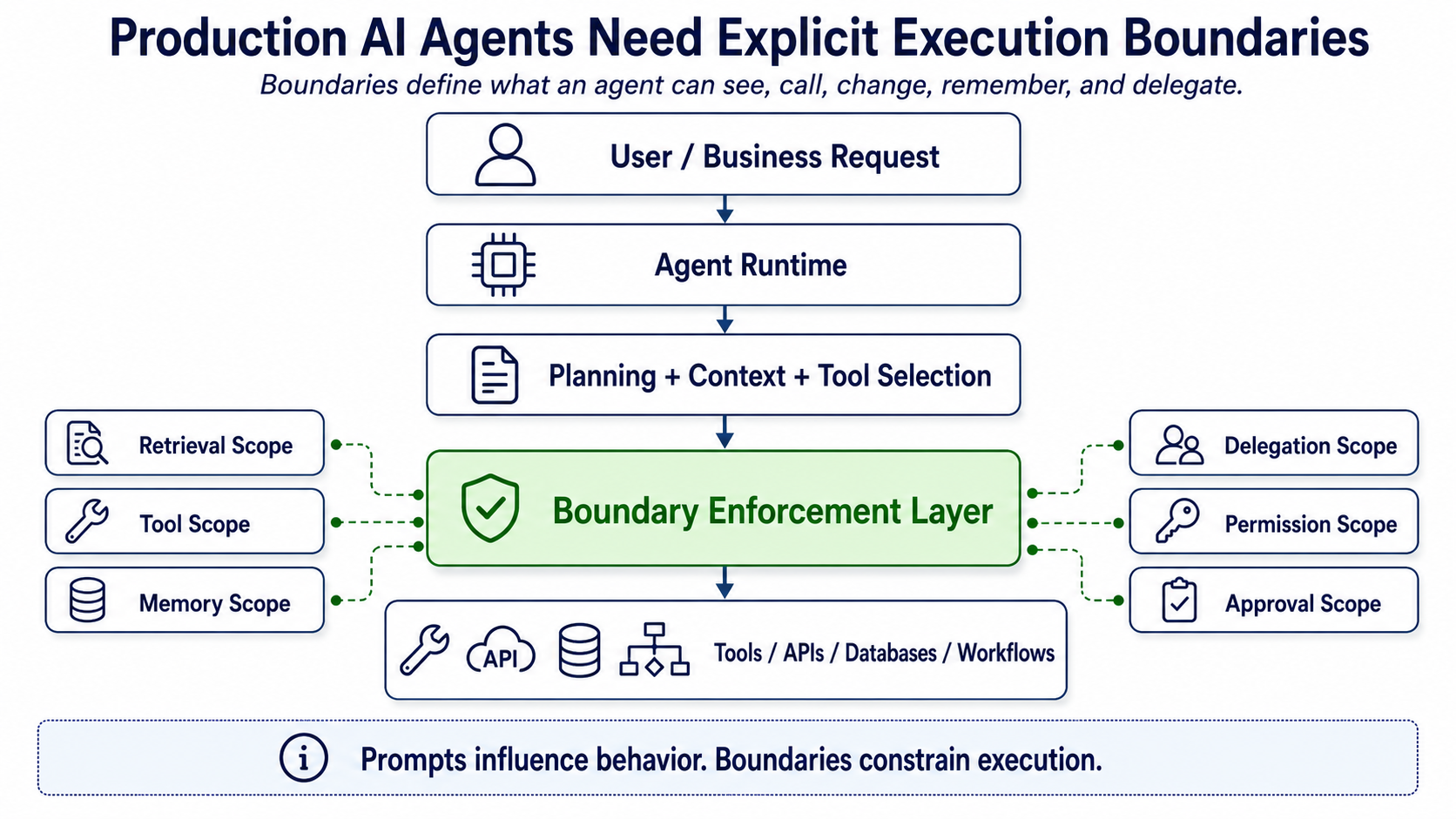
Figure 1: Production AI agents need explicit boundaries around context, tools, memory, delegation, permissions, and workflow execution.
What Is an Execution Boundary?
An execution boundary is the runtime limit that defines what an agent is allowed to see, decide, call, delegate, remember, or change.
For a production AI agent, boundaries can exist around:
- what data it can retrieve
- which tools it can call
- which users it can act for
- which systems it can modify
- which workflows it can trigger
- which agents it can delegate to
- which memory it can read or update
- which actions require approval
- which state transitions are allowed
This is not the same as a prompt instruction.
A prompt may say:
Do not access customer billing data.
An execution boundary prevents the agent from accessing customer billing data in the first place.
That distinction matters.
Prompts influence behavior. Boundaries constrain execution.
Production systems need both.
Why This Problem Is Emerging Now
Early AI assistants were mostly passive.
They answered questions, summarized text, drafted emails, and helped users reason through information.
Modern agents are different.
They increasingly operate through protocols, tools, retrieval systems, orchestration runtimes, and memory layers. The Model Context Protocol, for example, provides a standardized way for LLM applications to connect with external data sources and tools. That connectivity is useful, but it also expands the surface where authority, trust, and execution can become ambiguous.
The risk is no longer only that the model produces the wrong answer.
The risk is that the system takes a plausible action through the wrong path.
That action might use the wrong context, inherit the wrong permission, call the wrong tool, cross the wrong data boundary, or delegate work to the wrong downstream agent.
The final answer may look correct.
The workflow may still have been unsafe.
Safe Outputs Can Still Come From Unsafe Workflows
One of the hardest parts of production agent reliability is that boundary failures are often invisible at the surface.
A workflow can return the right-looking answer and still violate an operational constraint internally.
A support agent might answer a customer correctly after retrieving context from the wrong tenant.
A finance agent might summarize an invoice accurately after using a tool chain that should have required approval.
A code agent might generate a valid patch after reading files outside the intended repository scope.
A coordinator agent might delegate work to a specialist agent that inherits broader permissions than the original user had.
The result can look useful.
The execution path can still be wrong.
That is why final-output evaluation is not enough.
Production readiness has to include execution-path evaluation.
Boundary Failure Mode 1: Retrieval Contamination
Retrieval systems are often treated as context providers.
In production agents, they become authority surfaces.
If an agent retrieves unauthorized, stale, irrelevant, cross-tenant, or policy-restricted context, the model may reason correctly over the wrong evidence.
That creates retrieval contamination.
The dangerous part is propagation.
Bad context can move into:
- the prompt
- the agent's plan
- tool parameters
- memory
- downstream delegation
- future workflow state
By the time the final response appears, the original boundary violation may be hidden several steps upstream.
A production retrieval system therefore needs more than relevance ranking.
It needs retrieval-boundary enforcement.
That means validating permissions, freshness, tenant scope, policy constraints, and context provenance before retrieved content reaches the model.
Boundary Failure Mode 2: Unsafe Tool Chaining
Tool use is what makes agents valuable.
It is also what turns them into execution systems.
A single tool call may be safe. A chain of individually safe tool calls may not be.
For example:
- retrieve customer history
- summarize account risk
- draft a refund recommendation
- update a ticket
- trigger a billing workflow
- send a customer email
Each step may be reasonable in isolation.
The full chain may cross an approval boundary.
This is where traditional permission models start to break down. A user may be allowed to read a record. An agent may be allowed to summarize it. A workflow may be allowed to draft a recommendation. But none of those facts automatically means the agent should be allowed to trigger the final business action.
OWASP's MCP security work highlights related risks such as tool poisoning, where compromised tools, plugins, schemas, or outputs can inject misleading context and manipulate model behavior.
The broader point is simple:
Tool access should not be treated as a plugin convenience.
It should be treated as a governed execution boundary.
Boundary Failure Mode 3: Delegation Leakage
Multi-agent systems introduce another boundary problem.
When one agent delegates work to another, what exactly is transferred?
The task? The context? The permissions? The memory? The approval state? The user's authority? The workflow's authority?
If this is not explicit, delegation becomes a source of privilege leakage.
A coordinator agent may have access to broad context for planning. A specialist agent may only need a narrow slice of that context to complete a subtask. If the specialist inherits everything, the system has expanded authority without a deliberate policy decision.
Delegation should not mean automatic inheritance.
Every handoff should answer four questions:
- What is the downstream agent allowed to know?
- What is it allowed to do?
- What authority is it acting under?
- What evidence must it return?
Without those controls, multi-agent orchestration becomes difficult to audit and easy to over-permission.
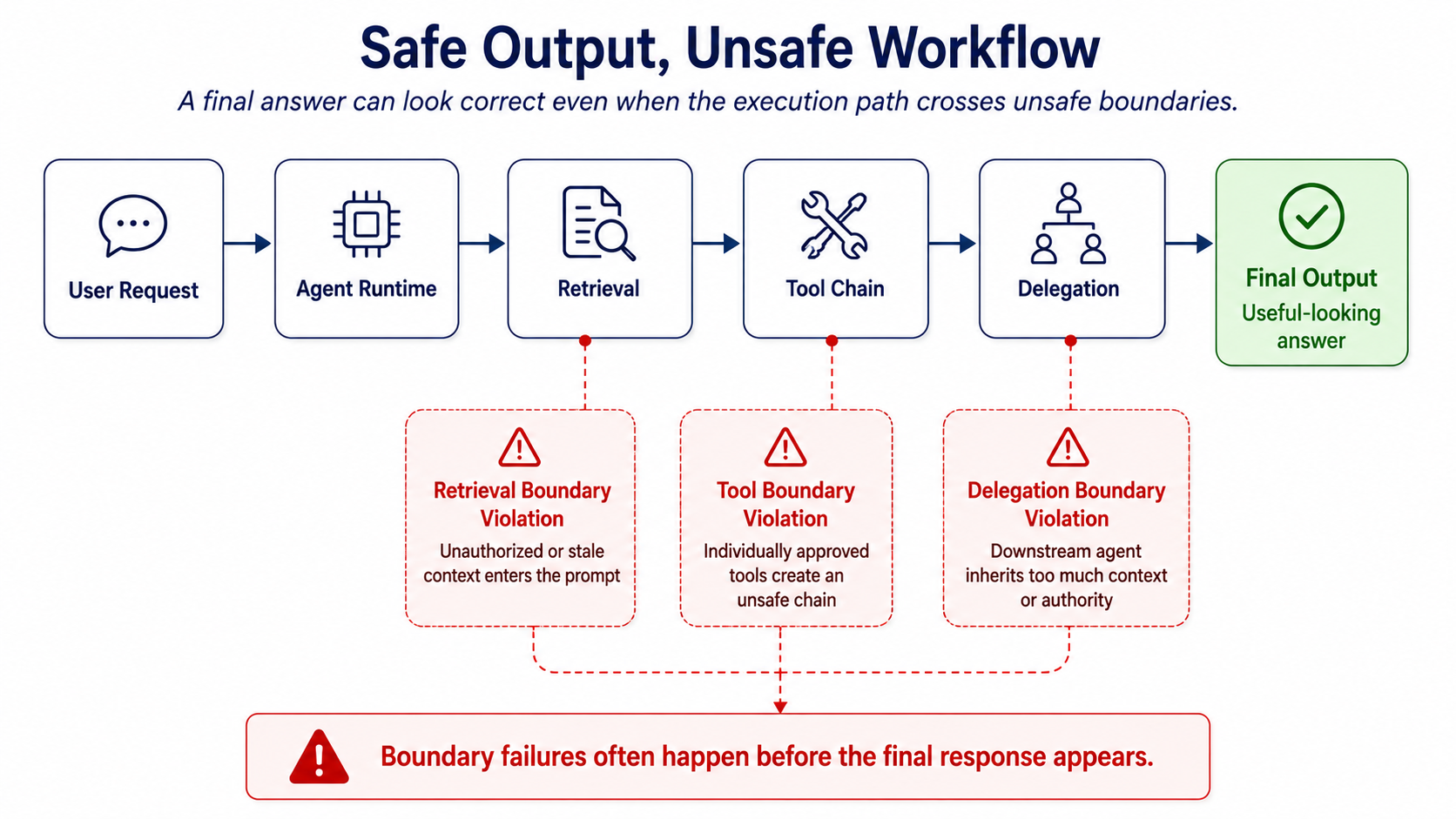
Figure 2: A production agent can produce a useful final answer while still crossing unsafe retrieval, tool, delegation, or memory boundaries during execution.
Boundary Failure Mode 4: Memory Contamination
Memory makes agents more useful because it allows them to retain preferences, facts, decisions, and workflow state.
It also creates a new execution boundary.
What should an agent remember? Who can write to memory? Which memories apply to which user, tenant, team, or workflow? When should memory expire? Which memories are safe to reuse in future tasks?
If memory is treated as a general-purpose context bucket, it can become a long-lived contamination layer.
A temporary assumption can become persistent state. A stale decision can become future evidence. A malicious instruction can become recurring behavior. A cross-user detail can leak into another workflow.
Production memory needs explicit write boundaries, read boundaries, retention policies, and provenance.
The question is not only whether memory improves personalization.
The question is whether memory remains inside the correct operational scope.
Boundary Failure Mode 5: Non-Interruptible Execution
Agents increasingly run across long workflows.
Some workflows may last seconds. Others may last minutes, hours, or days.
That creates a reliability problem.
If an agent is executing a multi-step process and crosses a boundary midway, can the system stop it?
Can it pause? Can it checkpoint? Can it resume safely? Can it roll back? Can it reconstruct what happened?
Durable execution frameworks are becoming important because they preserve workflow state across execution steps. LangGraph's durable execution documentation describes using a checkpointer so graph execution can be resumed later. Its interrupt mechanism also supports pausing execution, saving graph state, and resuming with additional input.
This matters because boundary enforcement is not only about blocking the first bad action.
It is also about stopping a workflow before a small violation becomes a larger operational incident.
Why Observability Alone Is Not Enough
Observability is necessary.
It lets teams reconstruct what happened across prompts, retrieval calls, tool invocations, policy checks, evaluator outputs, and business outcomes.
But observability by itself does not prevent unsafe execution.
It can tell you that an agent crossed a boundary. It may not stop the agent from crossing it.
That is why production systems need both telemetry and enforcement.
OpenTelemetry's generative AI work is moving toward standardized semantic conventions for AI-agent observability. OpenAI's Agents SDK tracing captures events such as LLM generations, tool calls, handoffs, guardrails, and custom events during agent runs.
These are important signals.
But the next architectural step is using those signals as part of a runtime control system.
A trace should not only help debug the past.
It should help enforce the present.
The Emerging Pattern: Boundary-Aware Agent Runtime
The emerging production pattern is clear.
The agent runtime needs a boundary enforcement layer between reasoning and execution.
That layer should decide:
- whether retrieved context can enter the prompt
- whether a tool can be called for this user and task
- whether a tool chain is allowed as a sequence
- whether a delegation is allowed
- whether memory can be read or written
- whether a workflow should pause for approval
- whether execution should continue, stop, or escalate
This is where agent architecture starts to look more like distributed systems engineering, security engineering, and platform engineering.
A model can propose. An orchestrator can plan. But the runtime must enforce.
Recent research points in the same direction. AgentTrace frames structured runtime logging as a foundation for security, accountability, and real-time monitoring in agent systems. A runtime governance paper argues that the execution path itself is the central object for effective governance.
That is the right framing.
The execution path is where agent risk becomes operational reality.
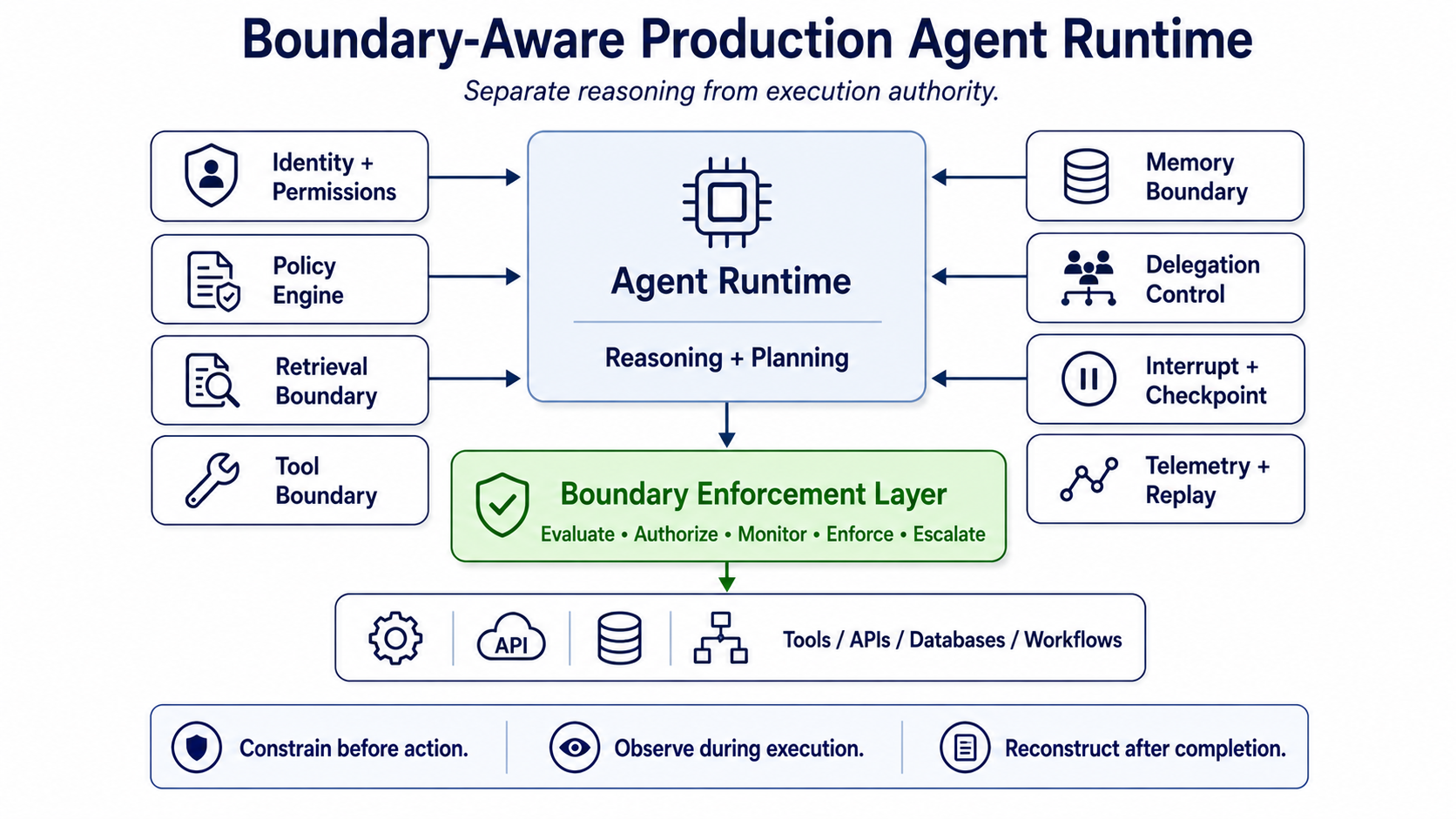
Figure 3: A boundary-aware agent runtime separates reasoning from execution authority and enforces policy across retrieval, tools, memory, delegation, checkpoints, telemetry, and audit trails.
The Production Architecture Shift
The old agent stack looked like this:
Model + Prompt + Tools
The production stack increasingly looks like this:
Model + Context + Tools + Memory + Orchestration
+ Identity + Policy + Boundary Enforcement
+ Observability + Replay + Auditability
The difference is not cosmetic.
The first stack optimizes for capability.
The second stack optimizes for controlled execution.
That is the shift from prototype to production.
What Engineering Teams Should Do
Before scaling agents into real workflows, teams should define execution boundaries explicitly.
A practical checklist:
-
Define the agent's execution scope. What can this agent see, call, change, remember, and delegate?
-
Separate orchestration from authority. The fact that an agent can plan a step should not mean it has authority to execute that step.
-
Scope tools by user, task, environment, and risk. Tool access should vary by workflow context, not remain globally available.
-
Enforce retrieval boundaries before context reaches the model. Validate tenant, permission, freshness, corpus version, and policy scope.
-
Add approval gates for high-impact actions. Payment changes, permission updates, customer communication, production writes, and legal or compliance actions should not be treated like ordinary tool calls.
-
Make delegation explicit. Each handoff should define transferred context, allowed actions, authority, and required evidence.
-
Add checkpoints to long-running workflows. Agents should be pausable, resumable, inspectable, and recoverable.
-
Log boundary events, not only model events. Record when boundaries are checked, crossed, blocked, escalated, or modified.
-
Version execution policies. A trace should show not only what happened, but which policy version allowed or blocked the action.
-
Test boundary violations before launch. Simulate stale retrieval, unauthorized context, prompt injection, excessive agency, tool chaining, memory contamination, and delegation leakage.
If most of these controls are missing, the system may still be useful.
But it should not be treated as governed autonomy.
It is assisted automation with unmanaged execution risk.
The Trade-Off
There is a real trade-off.
Too little boundary enforcement creates unsafe autonomy.
Too much boundary enforcement can make agents rigid, slow, and frustrating.
The goal is not to block every action.
The goal is to allocate autonomy based on risk.
Low-risk actions can move quickly. Medium-risk actions can be reviewed or constrained. High-risk actions need stronger approval, logging, and rollback controls.
The more authority an agent has, the stronger its execution boundaries must be.
The Bottom Line
Production AI agents do not only need better reasoning.
They need better execution control.
As agents become more stateful, tool-enabled, retrieval-driven, and multi-agent, the hardest failures will not always look like bad answers.
They will look like valid-looking workflows that crossed unsafe operational boundaries.
That is why execution-boundary design is becoming a core production discipline.
The next generation of reliable AI systems will be defined not only by what agents can do, but by whether organizations can constrain, observe, interrupt, reconstruct, and audit how agents do it.
The question is no longer only:
Can the agent complete the task?
The better question is:
Can the agent complete the task while staying inside the right execution boundaries?
That is the standard production AI agents need to meet.
Anything less is not trusted autonomy.
It is unmanaged execution.
What is your weakest boundary today: retrieval, tools, delegation, memory, or long-running workflow state?
Sources
- clype, The Invisible Failures of Production AI Agents: Why Observability Is the Critical Systems Layer
- clype, AI Agents Are Quietly Becoming a Privileged Runtime Layer
- Model Context Protocol, Specification
- OWASP Foundation, OWASP MCP Top 10
- LangChain, LangGraph Durable Execution
- LangChain, LangGraph Interrupts
- OpenTelemetry, AI Agent Observability - Evolving Standards and Best Practices
- OpenAI Agents SDK, Tracing
- arXiv, AgentTrace: A Structured Logging Framework for Agent System Observability
- arXiv, Runtime Governance for AI Agents: Policies on Paths